







細部まで詳細な画像をテキストから生成できるといわれているLumina Image 2.0をComfyUIで使って画像生成して見ました。
詳細な画像を生成するためのシステムプロンプトという機能やパラメータについて紹介します。
\生成AIにおすすめPC/

\操作性抜群のおすすめマウス/

Lumina Image 2.0とは
上海のAIラボのAlpha-VLLMが開発したモデルになります。
GoogleのGemma 2のテキストエンコーダーを使用しているとのことです。これにより、長文のテキストから詳細な画像を生成できるみたいです。
Apache 2.0ライセンス で公開されているため、商用利用も可能です。
ComfyUIでの実行
公式のWorkflowをとりあえず使用しました。
Ksamplerは普通のものでした。
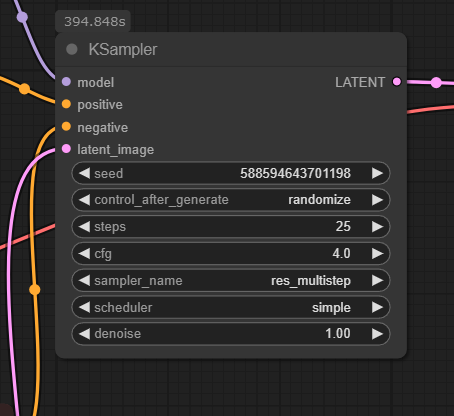
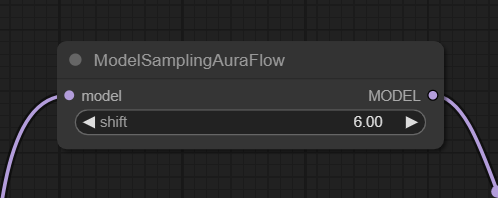
Lumina Image 2.0で特有のパラメータとしてはModelSamplingAuraFlowノードのshiftというものがありました。
また、workflow内には以下のようなコメントがありました。
Workflow内のコメント
| 英語 | Deeplでの日本語の翻訳 |
|---|---|
| The official way to sample this model is: shift 6 with 36 steps Sampling it with lower steps works but you might have to lower the shift value to reduce the amount of artifacts. Ex: 20 steps with shift 3 seems to not produce artifacts | このモデルをサンプリングする正式な方法は、36ステップのシフト6です。 より低いステップでのサンプリングは機能しますが、アーチファクトの量を減らすためにシフト値を下げる必要があるかもしれません。 例:20ステップ、シフト3ではアーチファクトは発生しないようです。 |
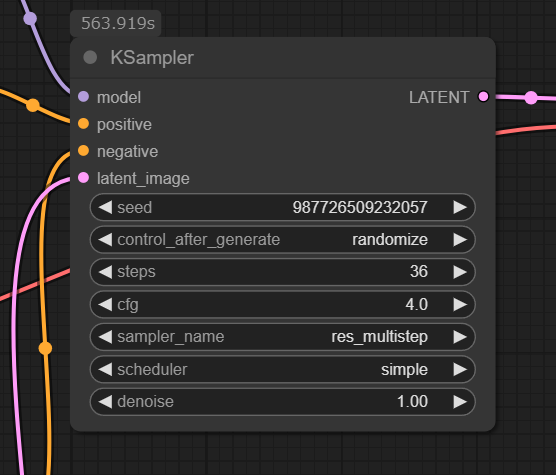
ModelSamplingAuraFlowノードのshiftが6でKSamplerのstepsが36が正式の方法とありますが、ダウンロードしたworkflowに設定されていた値はshiftが6に対してstepsが25になっていました。
最初から正式な方法の値にしておいてほしいと思いますが、コメントの通りにstepsの値を36にしました。
この値で実行したときにKsamplerでかかる時間は以下の画像のように9分くらいかかりました。
この時のバッチ数は1でしたので、1枚の画像を生成するのに9分くらいかかったことになります。
Lumina Image 2.0ではシステムプロンプトというものがあります。
具体的には、ダウンロードしたworkflow内のPositive Promptの<Prompt Start>以前の部分がシステムプロンプトになります。
そこには以下のようなプロンプトが入っていました。
ダウンロードしたWorkflow内にあったシステムプロンプト
| 英語 | Deeplでの日本語の翻訳 |
|---|---|
| You are an assistant designed to generate superior images with the superior degree of image-text alignment based on textual prompts or user prompts. | あなたは、テキストによるプロンプトやユーザーによるプロンプトに基づいて、画像とテキストの位置合わせの優れた度合いで優れた画像を生成するように設計されたアシスタントです。 |
これがあることでいい感じになるようです。
まとめ
長文のプロンプトでもちゃんと理解して詳細な画像を生成してくれますが、ところどころ歪みのような気になる部分はあることが多いです。










コメント