







以前にLTXVで画像を入力して動画を生成することについての記事を投稿しましたが、今回はテキストから動画生成をやってみましたので、そのやり方を紹介します。
\生成AIにおすすめPC/

\操作性抜群のおすすめマウス/

LTXVとは
ライトリックス(Lightricks)によって開発されたリアルタイムAIビデオ生成モデルであり、特に高品質な動画を迅速に生成する能力が注目されています。
このモデルは、拡散ベースの動画生成モデルです。テキストプロンプト(テキストから動画)または画像とテキストの組み合わせプロンプト(画像+テキストから動画)から動画を生成することができます。
このモデルの名称は、記載されているところによってはLTX-Videoと書かれていたりします。
CivitaiのフィルターのところはLTXVと書かれていて、Hugging FaceとGithubのページはLTX-Videoと書かれています。
LTXVは略称ということなのでしょうか。分かりません。
LTXVは画像から動画生成(i2v)とテキストからの動画生成(t2v)ができます。i2vの記事は以前書いたので、今回はt2vをやってみました。
ComfyUIでの実行
ライトリックスのGithubからダウンロードできるt2v用のWorkflowをとりあえず使用しました。
エラーがでる場合
メモリに関する以下のようなエラーが出る場合の対処は、別の記事で解説しています。
“Allocation on device”

ダウンロードしたWorkflowからの変更点
Prompt Enhancerというグループになっている、
Flux Prompt Enhanceを使用している以下の部分が正直、邪魔な気がします。
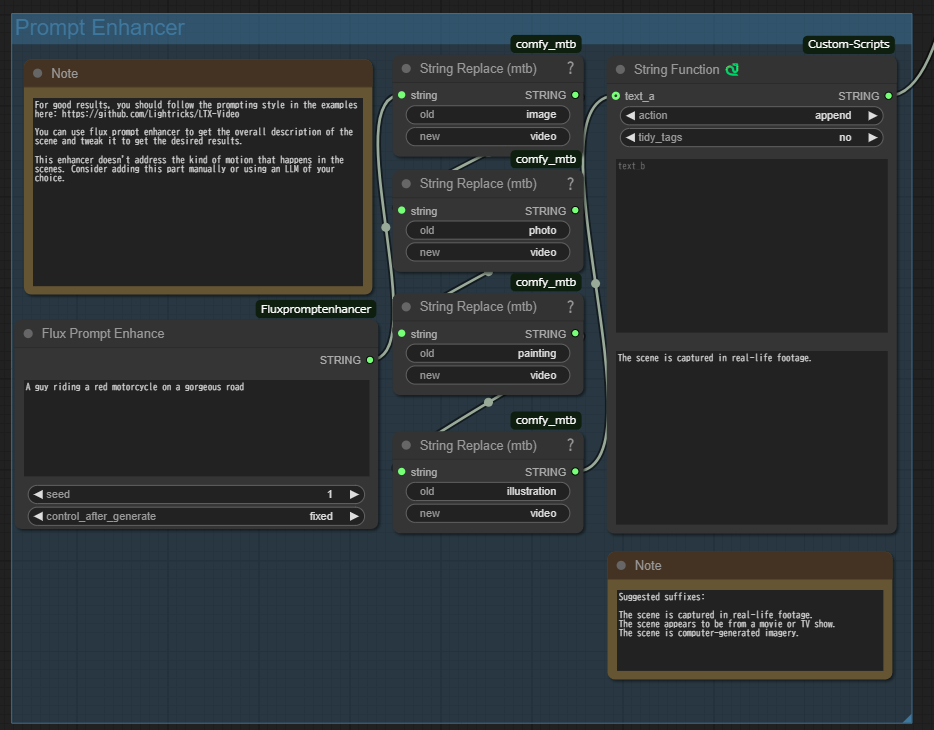
短い文章をいい感じに長くしてくれるみたいですが、生成される動画が意味不明なものになることが多かったです。
そのため、以下のように変更してしまいました。
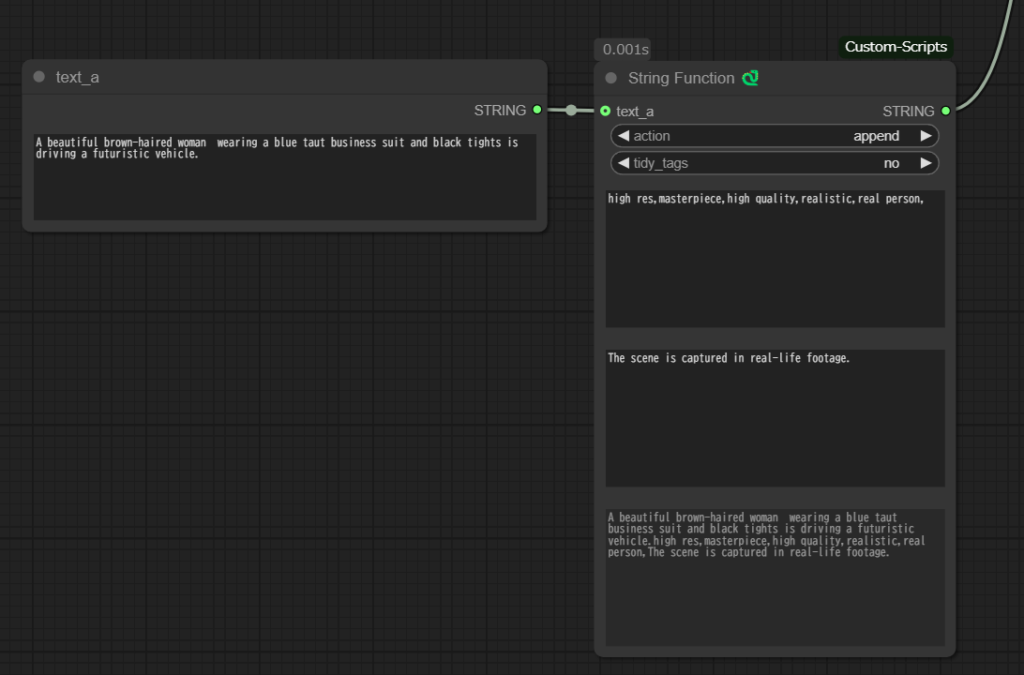
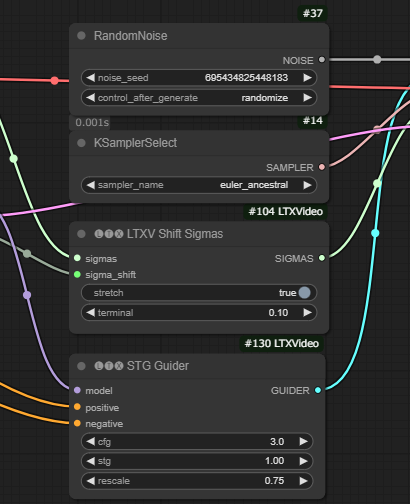
また、i2vの時と同様、RandomNoiseというノードの二つ目のパラメータのocntrol_after_generateの値がfixedになっていると、毎回同じものが生成されてしまうので、randomizeに変更しました。
生成にかかる時間
i2vと同様、SamplerCustomAdvancedノードで1分くらいかかっています。
パラメータについて
i2vと同様、以下の画像のLTXV Model Configuratorノードのパラメータのframes_number、frame_rate、img_compressionを変更することで、動画の長さを長くしたり、より大きな動きがある動画にしたりすることができます。
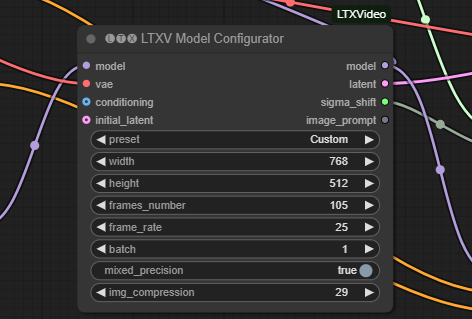
動画時間を延ばしたときのGPU RAMの使用率は、i2vより少ないように感じます。
i2vのときは変更してませんでしたが、LTXV Apply STGのblock_indicesも変更すると影響があるみたいです。
workflow内のコメントによると、11か14か19がいいみたいです。値を大きくすると動きが減るようです。
生成した動画
生成した動画と、入力したプロンプトを紹介します。
入力したプロンプト
| 英語 | 日本語の翻訳 |
|---|---|
| A brown-haired beautiful woman wearing a gray sleeveless shirt, white micro shorts and black tights is drives a futuristic vehicle.The scene is captured in real-life footage. | グレーのノースリーブシャツに白のマイクロショーツ、黒のタイツを履いた茶髪の美女が近未来的な乗り物を運転している。 そのシーンを実写で捉えた。 |
プロンプトの後ろの一文は、元のworkflowから追加されるようにノードが組まれていて、こういう映像に関するようなテキストが動画生成には必要みたいです。
まとめ
プロンプトが少し違うだけで落書きみたいな崩壊した動画になってしまったので、調整が大変でした。

動画生成AIに関する他の記事
Mochi 1の記事

商用利用に注意が必要なモデル

FramePackの記事











コメント