ComfyUIで動画生成AIであるLTXVを試してみたので、そのときのことを解説します。
実行したときに発生したエラーの対処と、参考になるように生成した動画も紹介します。
目次
LTXVとは
ライトリックス(Lightricks)によって開発されたリアルタイムAIビデオ生成モデルであり、特に高品質な動画を迅速に生成する能力が注目されています。
このモデルは、768×512の解像度で24FPSの動画を生成し、その速度は視聴するよりも速いという特性があります。
ComfyUIでの実行
ライトリックスのGithubからダウンロードできるWorkflowをとりあえず使用しました。
エラーが発生
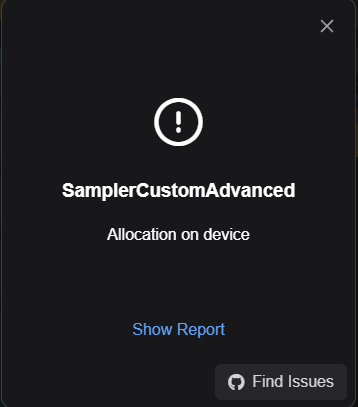
ComfyUIで実行したときに以下のエラー画面がでました。

エラーの文章は以下になります。
“Allocation on device”
調べたら、メモリが足りなくなるいわゆるOut of Memory(OOM)になっているということでした。
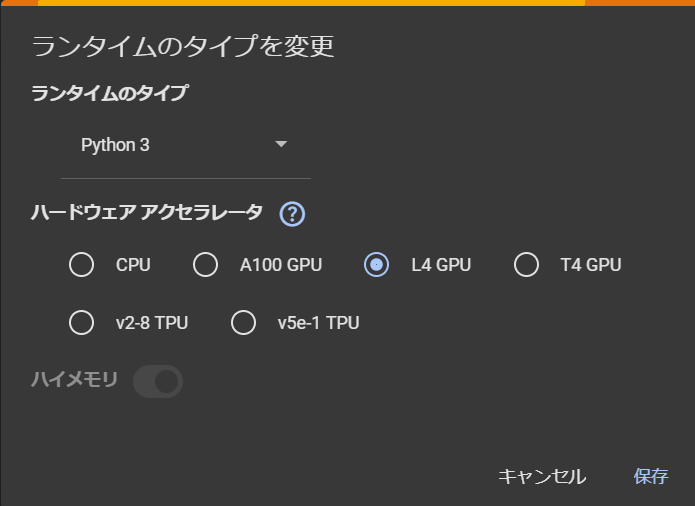
そのため、google ColaboratoryのランタイムのタイプでハードウェアアクセラレータをT4 GPUからL4 GPUに変更しました。
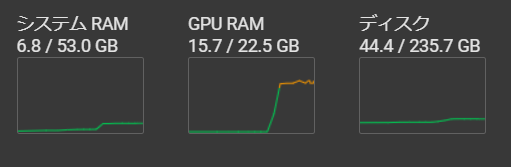
これで、GPU RAMは22.5GBまで使用できるようになります。
この状態で実行したら、GPU RAMは15.7GB使用していました。
ちなみに、ハードウェアアクセラレータをL4 GPUにしたときの1時間で消費するコンピューティングユニットは約2.4でした。
ダウンロードしたWorkflowからの変更点
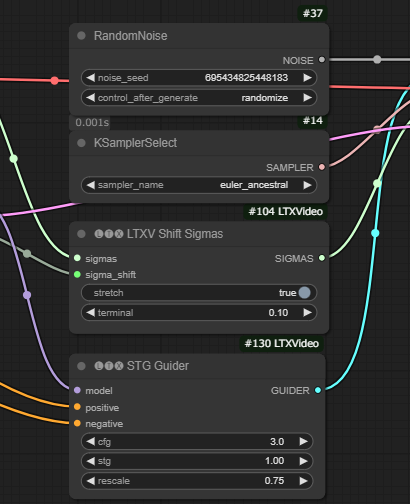
RandomNoiseというノードの二つ目のパラメータのocntrol_after_generateの値がfixedになっていると、毎回同じものが生成されてしまうので、ここをrandomizeに変更しました。
生成にかかる時間
SamplerCustomAdvancedノードで1分くらいかかっています。Mochi 1で1時間近くかかっていたことを考えると、圧倒的に早いです。ただ、GPU RAMは15GBを超えてしまうので、注意が必要です。
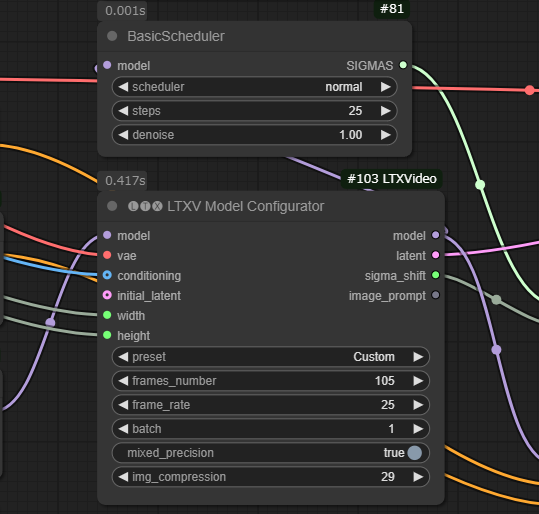
生成される動画に関連するパラメータについて
以下の画像のLTXV Model Configuratorノードのパラメータを変更することで、動画の長さを長くしたり、より大きな動きがある動画にしたりすることができます。
frames_numberの値を大きくすることで動画の長さが長くなります。
frame_rateの値を大きくすることで、動きが滑らかになる気がします。
img_compressionの値は、細かい動きが良くなる気がします。値を増やすときは、42くらいまでにした方がいい気がします。それより大きくすると、ノイズが多くなって元の絵がかなりくずれてしまう感じがします。動きがあまりない動画の場合は、29くらいでいい気がします。
これらのパラメータは、いずれも値を大きくするとGPUの使用率が上がるので、メモリが溢れてしまうOOMに注意してください。
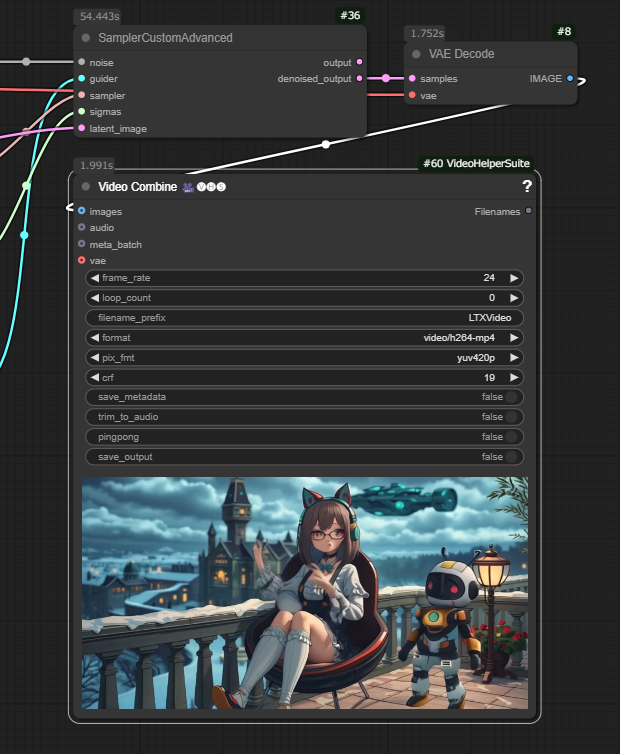
生成した動画
生成した動画と、入力した画像をサムネに使っている記事を紹介します。
その1
入力したサムネ画像を使用している記事
Hugging Faceのモデルで商用利用に注意が必要な動画生成AIモデルについて紹介します
ComfyUIで動画生成AIをやってみようと思って調べ始めたら、思いのほかライセンスが特殊だったので、Hugging Faceからダウンロードできるモデルで調べたものについて解説します。
その2
入力したサムネ画像を使用している記事
サムネ用の画像をComfyUIで生成したときのプロンプトを紹介します
画像生成AIで画像生成するときは入力として入れる文章、いわゆるプロンプトが重要になります。この記事では、このブログで使用しているサムネを生成したときのプロンプトを紹介します。
その3
入力したサムネ画像を使用している記事
ディープラーニング実装に関するエンジニア向け資格試験、E資格について受験に必要な条件や難易度・勉強…
G検定を運営する日本ディープラーニング協会(JDLA)が実施するもう一つの資格試験であるE資格について、受験資格、メリットやデメリット、勉強方法について紹介します。
その4
入力したサムネ画像を使用している記事
ComfyUIで使用できて商用利用もできる動画生成AIモデルであるMochi 1での動画生成のやり方を紹介します
ComfyUIで動画生成AIであるMochi 1を試してみたので、そのときのことを解説します。Mochi 1は商用利用できるモデルのため、参考になるように生成した動画も紹介します。
その5
入力したサムネ画像を使用している記事
データサイエンティスト協会が実施するDS検定★についてメリット・デメリットや難易度・勉強方法を紹介し…
データサイエンティスト協会が実施するデータサイエンティスト検定リテラシーレベル(略称:DS検定★)について、メリットやデメリット、難易度や勉強方法について紹介します。
その6
入力したサムネ画像を使用している記事
IT勉強会プラットフォームconnpassのオススメAI系コミュニティを紹介します
cnnpassは気軽にIT系の勉強会を開催できて誰でもそれに気軽に参加できるプラットフォームです。この記事ではAI系でオンラインで参加することができる勉強会や企業が開催するイベントを紹介します。
その7
入力したサムネ画像を使用している記事
ComfyUIに関する書籍がまだないので参考になりそうな別の書籍を紹介する
ComfyUIはまだできたばかりのものなので、まだ解説する書籍が存在しません。なので、別のStable DiffusionのWebUIの解説書籍などで、参考になりそうなものを紹介します。
その8
入力したサムネ画像を使用している記事
生成した画像を商用利用できるオススメのCivitaiのFluxモデルを紹介します
画像生成AIのモデルには商用利用を禁止しているものもあります。この記事ではComfyUIなどのWebUIで使用できるモデルをダウンロードできるサイトであるCivitaiにあるモデルで、商用利用できるFluxモデルを紹介します。
その9
入力したサムネ画像を使用している記事
ComfyUIがアップデートでUIがかなり変わって使い方が分からなかった話
久しぶりにComfyUIを起動したら何かUIがめちゃくちゃ変わってて困ってしまいました。いろいろ操作したりして分かったことを解説したいと思います。まだわからないこともたくさんあると思うので、分かり次第追記していきたいと思います。
その10
入力したサムネ画像を使用している記事
クラウドで画像生成AIやってるとパソコンのスペック関係ないけど使ってるノートパソコンを紹介する(つい…
Google ColaboratoryでComfyUIをやっていると正直使うPCは関係ないですが、自分が使っているノートPCを紹介します。使っていると言いつつも、もう売ってなかったので、同じシリーズのモデルを紹介します。ついでにGPUの設定についても解説します。
その11
入力したサムネ画像を使用している記事
「(エレコム)ゲーム用ボイスチャットミキサー(HSAD-GMMA10BK)」ガジェットレビュー
本来の用途とはちょっと違うけど、パソコンやスマホの音声とゲーム機の音声を一つの有線ヘッドフォンで聞くのに便利です。スマートフォンで通話しながら、ゲームの音をミックスして同時に再生できるゲーミングミキサーです。
その12
入力したサムネ画像を使用している記事
惨すぎるので苦手な人は注意!!「囚人転生」漫画レビュー
最近読んだ漫画を紹介します。芳文社公式まんがサービスのCOMIC FUZで連載中の囚人転生。著者はいとまん(原作)と、ホリエリュウ(作画)。かなり惨いので人は選ぶと思いますが、好きな人は好きだと思います。
その13
入力したサムネ画像を使用している記事
JDLAが実施するAI・ディープラーニングに関する資格試験、G検定についてメリット・デメリットや難易度・…
日本ディープラーニング協会(JDLA)が運営するAI・ディープラーニングに関する資格試験であるG検定について、メリットやデメリット、勉強方法について紹介します。
その14
この記事のサムネ。
動画の長さを延ばしています。
まとめ
15GBのGPU RAMではOOMになってしまってたので、ColabのハードウェアアクセラレータをL4 GPUに変更しました。
動画生成は1分くらいでできてしまうので、爆速です。
今回は画像から動画生成をしましたが、テキストからの生成もできるので今度試してみたいです。
ポチップ
動画生成AIに関する他の記事
LTXVでテキストから動画生成する記事
あわせて読みたい
LTXVをComfyUIで使ってテキストから動画生成するやり方を紹介します
以前にLTXVで画像を入力して動画を生成することについての記事を投稿しましたが、今回はテキストから動画生成をやってみましたので、そのやり方を紹介します。
Mochi 1の記事
あわせて読みたい
ComfyUIで使用できて商用利用もできる動画生成AIモデルであるMochi 1での動画生成のやり方を紹介します
ComfyUIで動画生成AIであるMochi 1を試してみたので、そのときのことを解説します。Mochi 1は商用利用できるモデルのため、参考になるように生成した動画も紹介します。
商用利用に注意が必要なモデル
あわせて読みたい
Hugging Faceのモデルで商用利用に注意が必要な動画生成AIモデルについて紹介します
ComfyUIで動画生成AIをやってみようと思って調べ始めたら、思いのほかライセンスが特殊だったので、Hugging Faceからダウンロードできるモデルで調べたものについて解説します。
FramePackの記事
あわせて読みたい
FramePackをComfyUIで使って2枚の画像から動画生成するやり方を紹介します
Colab上で実行したComfyUIでFramePackを使って動画生成してみました。動画の開始時用と終了時用の2枚の画像から動画生成するやり方を紹介します。
Wan 2.1の記事
あわせて読みたい
Wan 2.1をComfyUIで使ってテキストから動画生成するやり方を紹介します
Colab上で実行したComfyUIで動画生成モデルのWan 2.1を使ってみました。Wan 2.1はさまざまなことができますが、とりあえずテキストから動画生成するやり方を紹介します。
FramePackのLoRAの使い方
あわせて読みたい
ComfyUIでFramePackにLoRAを使うやり方を紹介します
ComfyUIでFramePackを使うためのFramePackWrapperにSelect Loraというカスタムノードが増えていたので、その使い方を紹介します。







































コメント