







Colab上で実行したComfyUIで動画生成モデルのWan 2.1を使ってみました。
Wan 2.1はさまざまなことができますが、とりあえずテキストから動画生成するやり方を紹介します。
\生成AIにおすすめPC/

\操作性抜群のおすすめマウス/

ロジクール 公式ストア
¥16,050 (2026/03/18 02:05時点 | 楽天市場調べ)
目次
Wan 2.1とは
Wan2.1は、中国Alibaba製のオープンモデルです。
テキストから動画、画像から動画、動画編集、テキストから画像、動画から音声など、多様なタスクに対応しています。
ライセンスはApache 2.0です。
そのため商用利用が可能です。
ComfyUIでの実行
以下のサイトからモデルやComfyUIのワークフローをダウンロードできます。
URL:https://comfyanonymous.github.io/ComfyUI_examples/wan/
t2vのものをGoogle Colabで実行したComfyUIで使ってみました。

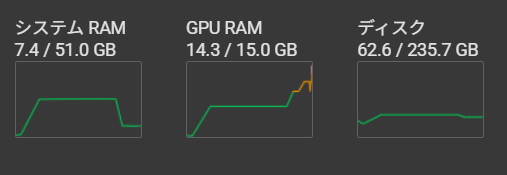
生成には365秒かかりました。

GPU RAMは最大のときで14.3GBになっていました。
動画の長さは、以下のEmptyHunyuanLatentVideoノードのlengthを変更すれば変えられます。
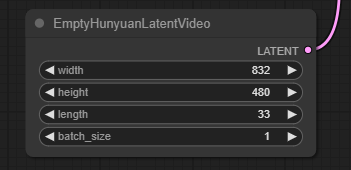
デフォルトでは33だったので、65に変更して生成してみました。

GPU RAMは瞬間的な最大値はあまり変わりませんでしたが、生成中の値は、33のときが11.1GBだったのに対して、12.6GBに増えていました。
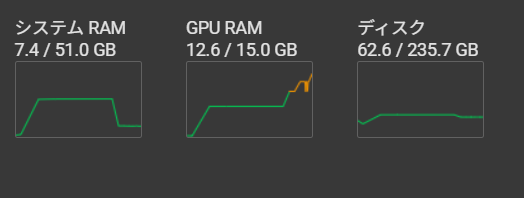
生成にかかる時間は、1093秒くらいで、結構伸びました。

まとめ
簡単にハイクオリティな動画が生成できた気がします。

動画生成AIに関する他の記事
LTXVでテキストから動画生成する記事
あわせて読みたい


LTXVをComfyUIで使ってテキストから動画生成するやり方を紹介します
以前にLTXVで画像を入力して動画を生成することについての記事を投稿しましたが、今回はテキストから動画生成をやってみましたので、そのやり方を紹介します。
Mochi 1の記事
あわせて読みたい

ComfyUIで使用できて商用利用もできる動画生成AIモデルであるMochi 1での動画生成のやり方を紹介します
ComfyUIで動画生成AIであるMochi 1を試してみたので、そのときのことを解説します。Mochi 1は商用利用できるモデルのため、参考になるように生成した動画も紹介します。
商用利用に注意が必要なモデル
あわせて読みたい

Hugging Faceのモデルで商用利用に注意が必要な動画生成AIモデルについて紹介します
ComfyUIで動画生成AIをやってみようと思って調べ始めたら、思いのほかライセンスが特殊だったので、Hugging Faceからダウンロードできるモデルで調べたものについて解説します。
FramePackの記事
あわせて読みたい

FramePackをComfyUIで使って2枚の画像から動画生成するやり方を紹介します
Colab上で実行したComfyUIでFramePackを使って動画生成してみました。動画の開始時用と終了時用の2枚の画像から動画生成するやり方を紹介します。










コメント